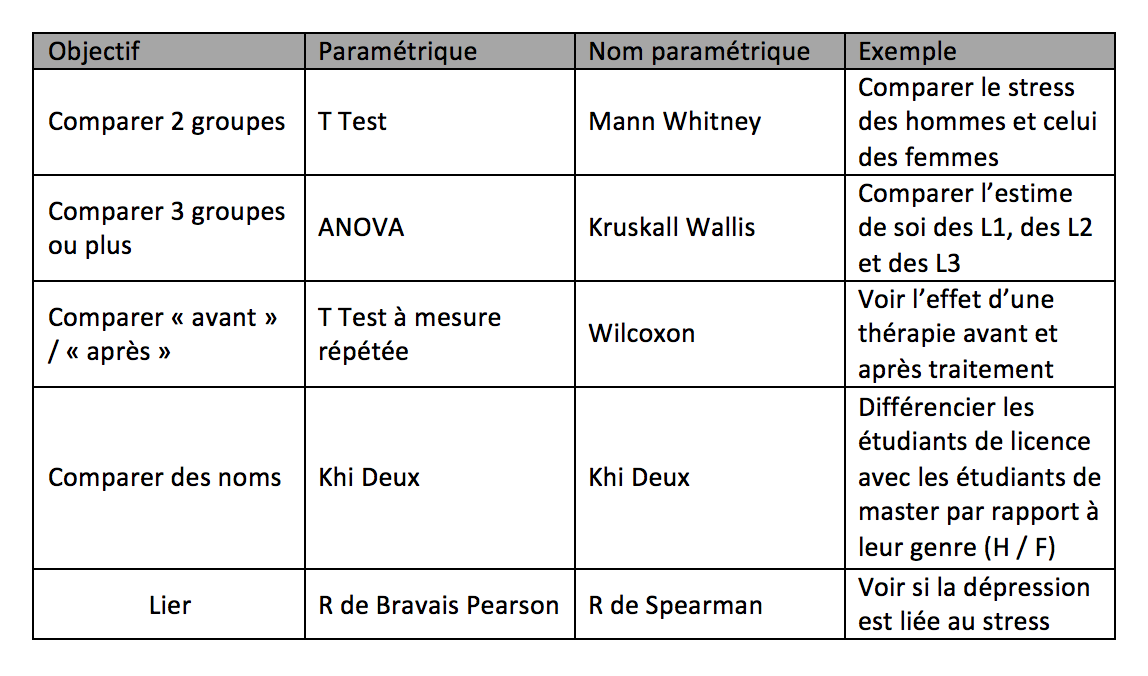
Pour chaque variable chiffrée (ordinale ou d'intervalle), il est possible de vérifier que les données suivent une loi normale. Pour cela, les données doivent être distribuées selon la courbe de Gauss. En effet, les données peuvent être représentées sous forme de graphique. Mais elles peuvent également être obtenues à partir de tests statistiques. Les plus connus sont le test du Shapiro-Wilk ou le test du Kolmogorov-Smirnov.
Les tests statistiques qui permettent de vérifier la normalité des données sont plus précis que les graphiques puisque les probabilités réelles sont calculées. Les tests de normalité calculent la probabilité que l'échantillon soit tiré d'une population normale.
Les hypothèses utilisées sont :
- Ho : les données de l'échantillon ne diffèrent pas significativement de celles d'une population normale.
- Ha : les données de l'échantillon sont significativement différentes de celles d'une population normale.
En statistiques, on cherche à trouver une différence entre les groupes. Lorsqu'on teste la normalité de données, nous ne cherchons pas à trouver une différence. En effet, nous voulons que nos données soient non différentes. Pour cela, il faut accepter l'hypothèse nulle.
Donc, lorsque vous testez la normalité :
- Si p > .05 : les données sont normales.
- Si p < .05 : les données ne sont pas normales.
Pour faire des tests paramétriques, il faut donc que les données suivent une loi normale, avec un p > .05 aux tests de normalité.