Traitement de données en tables
📝 Mini-cours GRATUIT
Le traitement des données structurées : lecture des données dans un fichier csv
Le traitement des données structurées : exemple 1
Le traitement des données structurées : exemple 2

📄 Exos type bac PREMIUM

Exercice 1

Exercice 2

Exercice 3
📄 Annale PREMIUM

Sujet zéro — Numérique et sciences informatiques
🍀 Fiches de révision PREMIUM

Systèmes d'exploitation

Python / Variables
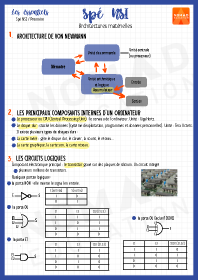
Architectures matérielles

Python : Fonctions – Librairies – Opérateurs booléens

Algorithmes de référence

Python : Structure de contrôle

Représentations des données : types construits
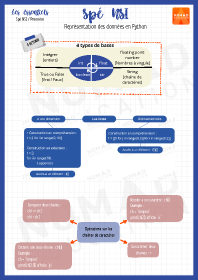
Représentation des données en Python

Spé NSI
📄 Annale PREMIUM
Sujet zéro — Numérique et sciences informatiques