Le Web
📝 Mini-cours GRATUIT
Les langages HTML et CSS
Les URL
Le modèle client-serveur
Le protocole HTTP
Les liens hypertextes
Les moteurs de recherche
Les sites Web dynamiques
Confidentialité des données

🎲 Quiz GRATUIT
🍀 Fiches de révision PREMIUM

Html et CSS

Html formulaire

Le réseau

Les réseaux sociaux

Python
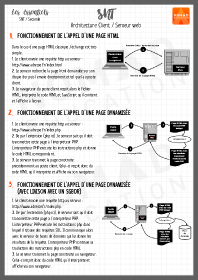
Architecture Client Serveur