Les données structurées et leur traitement
📝 Mini-cours GRATUIT
Repères historiques
Les formats des données
Quelques exemples de format de fichier stockant des données
Les bases de données
Les métadonnées
Les opérations effectuées sur les tables de données
Le stockage des données
Big Data et accès aux données

🎲 Quiz GRATUIT
🍀 Fiches de révision PREMIUM

Html et CSS

Html formulaire

Le réseau

Les réseaux sociaux

Python
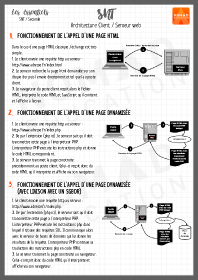
Architecture Client Serveur